A timelapse of a deepfake training run on Hank and John Green.
The face-swapping technology known as “DeepFakes” has been written about extensively over the last year — most recently by John Green in a video exploring the technology and the history of image manipulation. You may have heard mention of the technology from the silly fun of adding Nicholas Cage to, well, just about anything, the darker implications of using deepfakes for disinformation, or the deeply troubling discussion of the technology’s use for purposes of revenge porn. In this post, I’d like to briefly discuss what the technology does, how it works, and the questions this and similar technology raises.
How does it work?

There are many others excellent explanations of this technology, so I’ll give just a high-level explanation. I recommend Jonathan Hui’s article in particular.
Let’s say we want to make every face into John Green’s face with a mustache like I did in this silly video, and obtained John Green’s permission to use here — (also an explanation of the mustache in-joke for the uninitiated). Let’s start with his brother, Hank. First, we need to get the computer to learn what each face looks like in a abstract way. The spacing of the eyes, shape of the nose, presence or absence of a mustache. We can think of the computer learning a description of a face that it could give to a composite artist, as Jonathan Hui puts it. The algorithm is, in essence, learning how to take an image, store it in memory, and then is scored on how well it does at re-drawing that face from memory.

The algorithm being used in this case is a Convolutional Neural Network (CNN). This is also where the “deep” in “deepfakes” comes from. Neural networks have been around in computer science for a long time, but have regained popularity as “Deep” neural networks have shown to perform amazingly well at many machine learning tasks. CNNs operate by breaking the input data down into smaller chunks, and learning specific “features” about those chunks. For instance: Is this the edge of a face? Is this an eye?

A crucial fact about CNNs and neural networks in general, is that they learn by being told precisely how wrong they are, and can calculate how to make improvements on the next attempt. This is also why many researchers in machine learning fields are careful to mention that computational neural networks might be inspired by human brains, but do not function identically. Human babies aren’t given a score on 1 to 10 for learning things like “is that Mommy’s face?” and “What happens when I touch this hot stove?” We get feedback, sure, but it’s often implicit, rather than explicit feedback.
Back to our face swap algorithm, using the CNN to attempt to learn a description then re-draw a face millions of times and learning not to repeat previous bad guesses eventually starts to converge on a solution that looks pretty good. By sheer brute force, the system eventually learns what parts of the face mean what, without having any concept of what eyes, noses, or mustaches are!
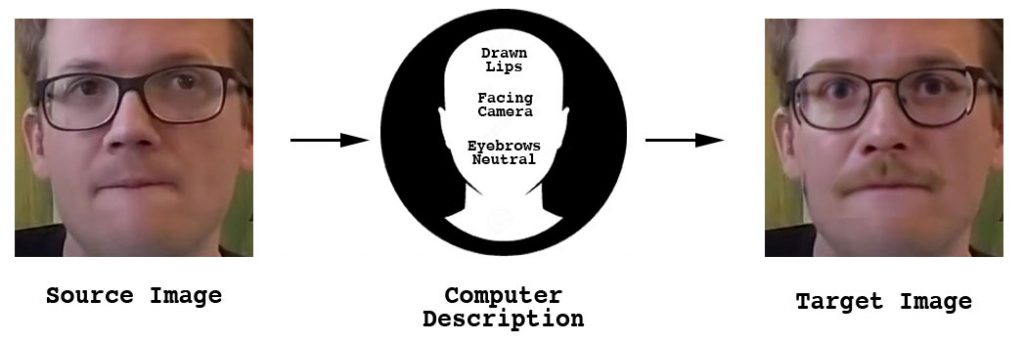
After learning a description for both the source face and the target face, we can then go through images of the person whose face we want replaced, get the description “Face A has: squinting eyes, a drawn upper lip in a smile, is facing the camera…” and then ask for the same description to be drawn, but with the characteristics of Face B.
So, What’s the Big Deal?
So, the main issues that have been raised in reporting deal with three main topics:
- Copyright
- Personality Rights
- Consent
Copyright and personality rights have to do with commercial value of content. If you wanted to make money swapping Nicholas Cage’s face into clips from movies this might (I am not a lawyer!) fall under fair use by means of parody. However, Nicholas Cage might have a legal basis to sue for the unlicensed use of his face. Legally speaking, it’s still a murky area, and I’m not going to get much further into this aspect here.
Outside the potential legal issues, the broader question that technology like this begins to raise is one of consent — what uses of technology like this should we consider morally okay? I personally do a lot of photography, and often take pictures of my friends at parties. Because we know each other, and that they look into my camera and smile when I point it their way, they are implicitly consenting to taking their picture, and I have asked in advance if I can put things on social media. Even though they gave permission for me to take that picture, it is with the implied agreement that it will be to document that party. If I then were to use that picture to write a blog post using their face to shame them for their behavior at that party, however, that’s clearly not something they gave explicit or implicit permission for.
Where do we draw the line for informed consent when it comes to media, particularly using people’s likenesses? It is an open question that Alan Zucconi’s tutorial does a good job of looking at more deeply.
What is “Public” Now?
While the legal and ethical issues surrounding deepfakes raise many deep and important questions, I think that they point to a bigger issue — that technology has moved faster than our cultural understanding of what “public” information is.
This is a question that I ask in my class on ethics in machine learning: does something posted on social media with permissions set to “public” mean the same thing as “not private?” On its face this seems obvious; if the author wanted it to be private, they would mark it as such. But compare this to being at a loud party speaking to a friend. Is this “public?” Kind of, perhaps you’re interested in other friends joining in the conversation, but this isn’t the same thing as addressing the whole room.
When it comes to social media, a lot of the way we talk culturally about “public” posts is the same as the way we think about news stories: it is text that has been “published.” But the process for “publishing” social media content is far different from how we used to think about published content. Before the internet, newspapers had a comments section of sorts in the form of letters to the editor. To get your comment on a story publicly available, you would have to write and mail a letter to the newspaper, and they would then print that, usually in a paper that was only distributed locally. Even for this small range of distribution, there was a fairly significant amount of time invested. As with my discussion of consent above, we culturally understood that in the process of spending that time to write your letter and mail it, you would’ve had plenty of time to think about, and commit to making your words (and possibly name) part of the public record.
Now, we are able to make our thoughts public instantly, without having a lot of time to think through in what ways we would want that information to be used. We might think as far as the fact that anyone might be able to read what we’ve written, but what about researchers using what you’ve written to create a bot that acts like you? Perhaps trying to learn jokes and memes that you and your friends use that might be used to make you laugh at a marketing campaign and buy the product? How about learning to guess your gender and race by looking at pictures you post, and comparing that against the words you use?
It might be surprising to learn that most research conducted in the US considers all of these uses fair game for researchers, because the data is considered “publicly available” in the same way that newspaper articles are. Is this really what people expect, though? When sociologists from the UK asked Twitter users this in 2017, most people said they’d expect to be asked first (Williams et al, 2017).
What do we do now?
I don’t really have any great answers to where we go from here, as this is a discussion that we are just starting to have. However, I have a few suggestions to start discussing:
Terms of Service
I think it’s important that we begin to question companies’ Terms of Service, since it’s a common joke that nobody really reads them, and thus the companies have not truly asked for meaningful consent. Meaningful, informed consent in human subject ethics implies not only that you’ve asked for consent, but verified that the subject understands fully what the information you collect will be used for. This is in no way what ToSs are doing.
Redefining The “Publicly Available” Standard
As I outlined above, the standard for “publicly available” seems to me to be based on an outdated understanding of what it means to make your words publicly available. We as a society realize that human beings are impulsive, and take that into account in our legal system in many ways — if you kill another person in “the heat of passion,” in many cases this results in a lesser charge. Suicide barriers are built with the understanding that suicides often stem from an impulsive response to the call of the void, not thorough planning. I think that we need to factor in such ideas of human impulsivity into our definitions of what is “public,” at least so far as re-reporting, or research ethics are concerned.
Improve our Critical Thinking and “Ethical Imaginations”
For academics and end-users alike, deepfakes, and similar technology that might be used to imitate an author’s style in text, or learn to generate soundalike audio of a person’s voice (things that I will discuss in a later post), all point to an increasing need for developing our skills for critical thinking and skepticism as a society. It is well outside my field of expertise, but wonderful work is being done by my colleagues at the University of Washington, and I recommend taking a look of their list of resources for activities, or Carl Bergstrom and Jevin West’s course Calling Bullshit: Data Reasoning in a Digital World. (A further resource to take a look at is Crash Course’s series on Navigating Digital Information!)
On the practicioner and researcher side, one the principles in Data for Democracy’s Community Principles on Ethical Data Practices is that data practitioners “…take responsibility for exercising ethical imagination in [our] work…” I find this to be a wonderful phrase, because as in my experience attempting to teach ethics, I have realized that the ultimate goal of ethics can’t be to give answers — absolutes are nearly impossible — but to encourage thought. This is often cast as a critical, negative practice: decrying unethical practices and censuring offenders. But envisioning a technology’s use in the future is also a creative process that we can think of as additive to our understanding of the world, rather than limiting.
I have many more thoughts, but if you’re interested in learning more, I would recommend taking a look at The Ethics of Online Research, which talks a great deal further about these issues — and if you’re interested in potentially joining our program, take a look at the Master of Science in Computational Linguistics at the University of Washington.
Thanks for reading, and enjoy your pizza!
Thanks to John & Hank Green for use of this video to show the faceswap in the most in-jokey way possible. (Watch their original video here!)
1 Comment
Dan
June 17, 2019 - 6:26 amThat was a good read,thanks